Pagination is a technique for limiting output. Think of Google search results, shopping the electronics category on Amazon, or browsing tagged questions on Stack Overflow. Nobody could consume all of the results in a single shot, and no site wants to spend the resources required to present them all to us, so we are offered a manageable set of results (a “page”) at a time.
In the most basic cases, we can implement this functionality in SQL Server by using OFFSET/FETCH. The problem is that anything that uses TOP or OFFSET will potentially have to scan everything in the index up until the page requested, which means that queries become slower and slower for higher page numbers. To achieve anything close to linear performance, you need to have a narrow, covering index for each sort option, or use columnstore as Erik Darling recommends here, or concede that some searches are just going to be slow. Throw in additional filtering, pulling data from other tables, and letting users dictate any sort order they want, and it becomes that much harder to tune for all cases.
I have a lot that I want to say about paging, and I will follow up with more content soon. Several years ago, I wrote about some ways to reduce the pain here, and it is long overdue for a refresh. For today’s post, though, I wanted to talk specifically about pagination when you have to order by large values. By “large” I mean any data type that can’t fit in an index key, like nvarchar(4000) or, really, anything that can’t lead in an index and/or would push the key past 1,700 bytes.
An Example
Let’s say we have a Users table on SQL Server 2022:
CREATE TABLE dbo.Users
(
UserID int IDENTITY(1,1) NOT NULL,
CreationDate datetime2(0) NOT NULL
DEFAULT sysutcdatetime(),
DisplayName nvarchar(200),
Reputation int NOT NULL
DEFAULT 0,
Email nvarchar(320),
AboutMe nvarchar(4000),
CONSTRAINT PK_Users PRIMARY KEY(UserId)
);
And let’s populate that table with a million rows (which I update after the insert to use an expression against the identity column):
INSERT dbo.Users(AboutMe)
SELECT name FROM
(
SELECT TOP (1000000) sc.name
FROM sys.all_columns AS sc
CROSS JOIN sys.all_objects AS so
) AS x
ORDER BY NEWID();
UPDATE dbo.Users SET
DisplayName = N'U' + RIGHT(CONCAT('000000',UserID),7),
Email = CONCAT(LEFT(NEWID(),18),N'@gmail.com');
Spot checking the first few rows:
SELECT TOP (10) UserID, DisplayName, Reputation, Email, AboutMe FROM dbo.Users;
Let’s also say that the user interface that lets you page through these users, 25 at a time, lets you sort by any of these columns – including AboutMe. If you’re already getting hives, I don’t blame you.
We’ll use dynamic SQL (a la the kitchen sink approach, also due a refresh) for the initial paging mechanism, supporting a different plan for each sort option. I’m going to leave out error handling for brevity, and stick to the simple case where we’re just browsing all users in some defined order (filtering will come later). We’ll skip right to the case where we use a CTE to first derive just the key values before we pull the rest of the information, e.g.:
WITH keys AS
(
SELECT UserID,
rn = ROW_NUMBER() OVER
(ORDER BY /* something */)
FROM dbo.Users
)
SELECT u./* all relevant columns */
FROM dbo.Users AS u
INNER JOIN keys AS k
ON u.UserID = k.UserID
WHERE k.rn > ((@PageNumber - 1) * @PageSize)
AND k.rn <= (@PageNumber * @PageSize)
ORDER BY k.rn;
For the procedure in my test rig, I’m adding two additional parameters that you wouldn’t use in production: @TestNumber for evaluating performance, and @Output to suppress rendering results (I’ll dump the rows into a #temp table, so I can run lots of tests without overwhelming SSMS). I also use MAXDOP to exaggerate the impact without parallelism. Here’s how the initial procedure looks:
CREATE OR ALTER PROCEDURE dbo.PagingAllUsers
@SortColumn nvarchar(128) = N'UserID',
@SortOrder char(4) = 'ASC',
@PageNumber int = 1,
@PageSize tinyint = 25,
@TestNumber int = 1,
@Output bit = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql nvarchar(max) = CONCAT(N'
DROP TABLE IF EXISTS #o;
WITH keys AS
(
/* Test# ', @TestNumber,
' - ', @SortColumn, ' - ', @SortOrder,
' - ', @PageNumber, ' */',
N'SELECT UserID, rn = ROW_NUMBER() OVER
(ORDER BY ', QUOTENAME(@SortColumn),
N' ', @SortOrder, ')
FROM dbo.Users
)
SELECT u.UserID,
u.CreationDate,
u.DisplayName,
u.Reputation,
u.Email,
u.AboutMe',
CASE WHEN @Output = 0 THEN N' INTO #o ' END,
N' FROM dbo.Users AS u
INNER JOIN keys AS k
ON u.UserID = k.UserID
WHERE k.rn > ((@PageNumber - 1) * @PageSize)
AND k.rn <= (@PageNumber * @PageSize)
ORDER BY k.rn
OPTION (MAXDOP 1);');
EXEC sys.sp_executesql @sql,
N'@PageNumber int, @PageSize int',
@PageNumber, @PageSize;
END
Now, this code and this table and this data may produce slightly different plans on your machine, with or without MAXDOP, due to a variety of reasons. But the impact seen in the plans and runtime should be similar.
The good sort
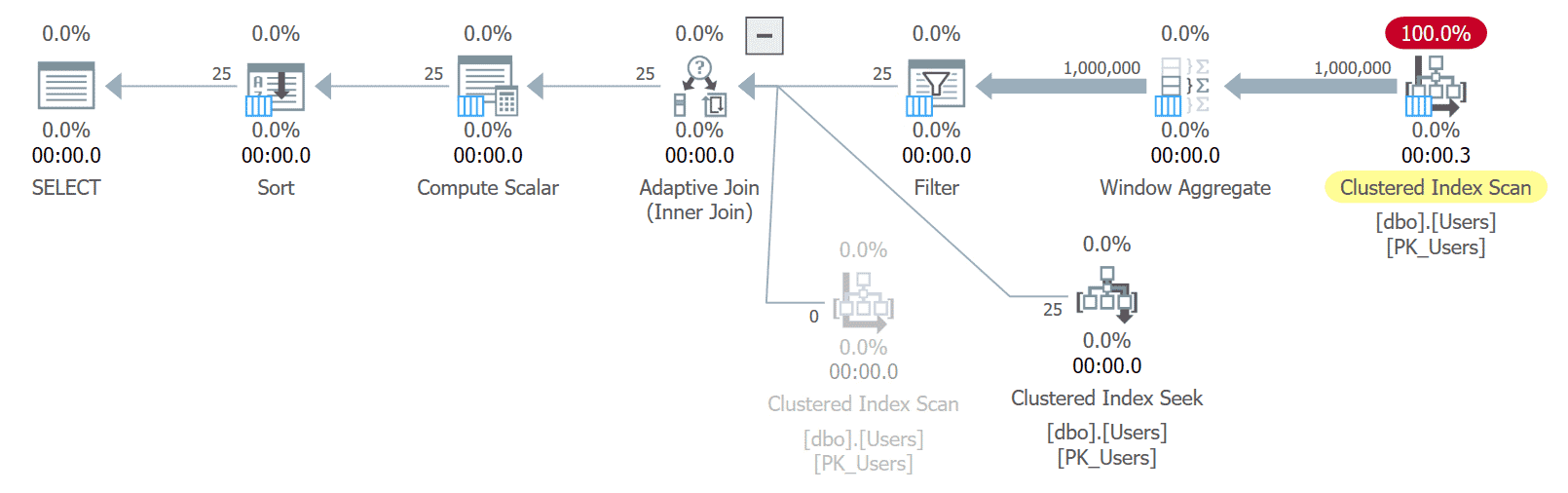
This technique works great, of course, when we sort by the UserID column (in either direction):
DECLARE @SortColumn sysname = N'UserID';
EXEC dbo.PagingAllUsers @SortColumn = @SortColumn,
@PageNumber = 1, @Output = 1;
EXEC dbo.PagingAllUsers @SortColumn = @SortColumn,
@PageNumber = 40000, @Output = 1;

With a supporting index, even though it’s wide, no work is spent sorting. You can see how late in the plan the sort operator is introduced; after we’ve already filtered down to 25 rows:
The bad sort
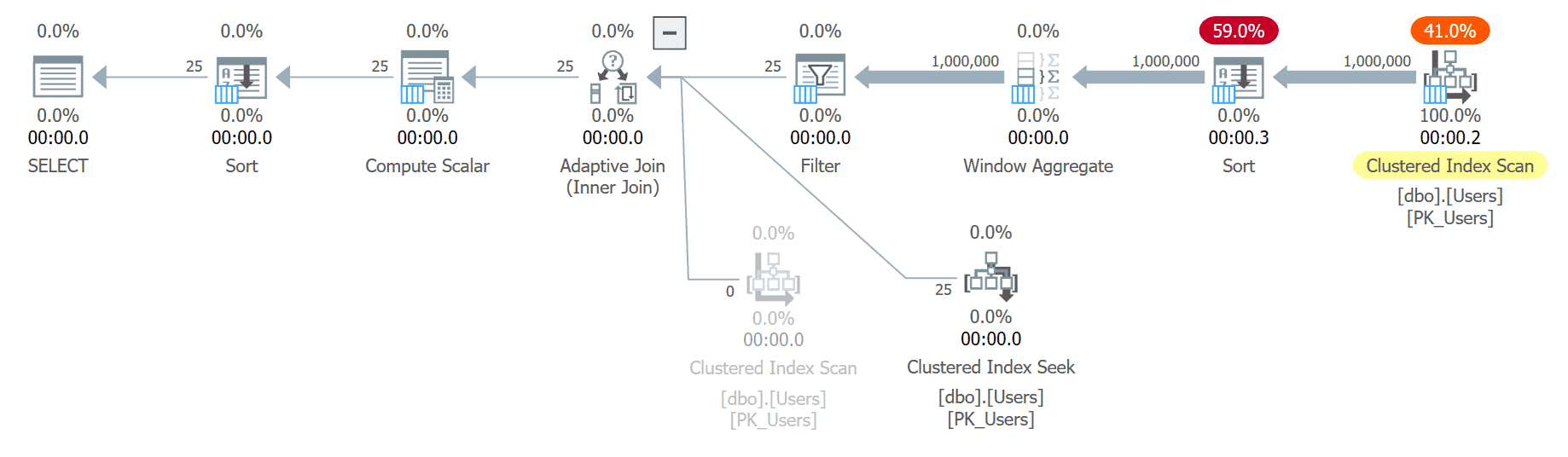
But let’s pretend there is a very good reason to sort by the AboutMe column instead. When we put that in the ORDER BY, it gets ugly:
DECLARE @SortColumn sysname = N'AboutMe';
EXEC dbo.PagingAllUsers @SortColumn = @SortColumn,
@PageNumber = 1, @Output = 1;
EXEC dbo.PagingAllUsers @SortColumn = @SortColumn,
@PageNumber = 40000, @Output = 1;

The sort has to occur much earlier in order to locate the 25 rows we need:
What can we do when we have to sort by some column that can’t be sorted efficiently?
Saved by columnstore?
Often, a non-clustered columnstore index can compensate for the “I want to sort by any column but I don’t want to index every column” issue, as each column acts as its own little mini-index in a way. But it doesn’t help much in this case:
CREATE NONCLUSTERED COLUMNSTORE INDEX IX_NCCI ON dbo.Users(UserId, DisplayName, CreationDate, Reputation, Email, AboutMe);

The plans for both sort options are quite similar but, again, pay particular attention to where the sort happens (for UserID it’s after we’re down to 25 rows; for AboutMe it’s against all 1MM):
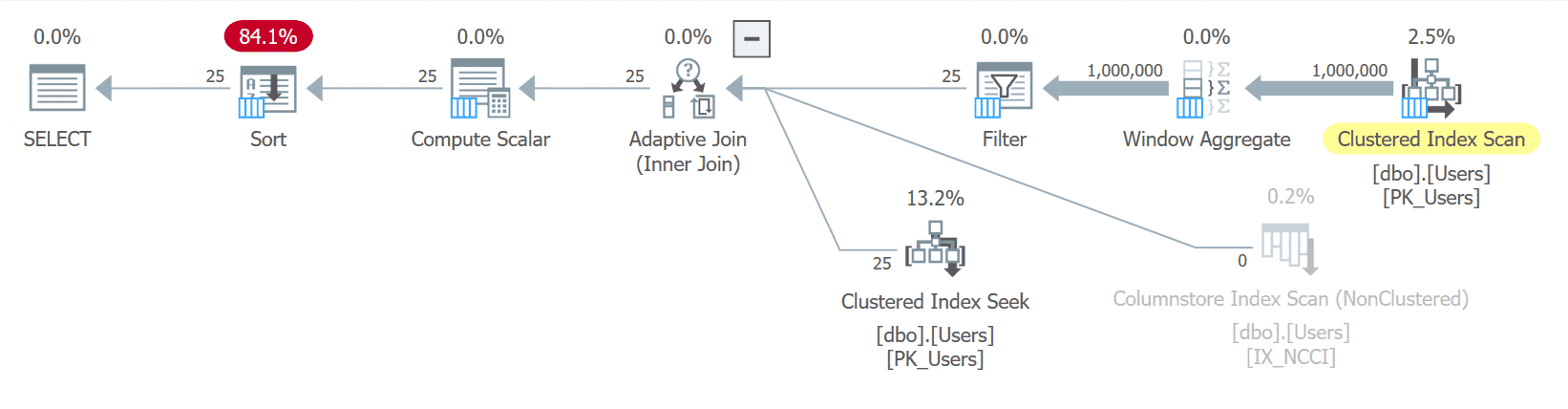
While the sort may have been more efficient against fewer pages, it still has to sort all one million values – whether the 25 rows we’re after are at the beginning or end of the set.
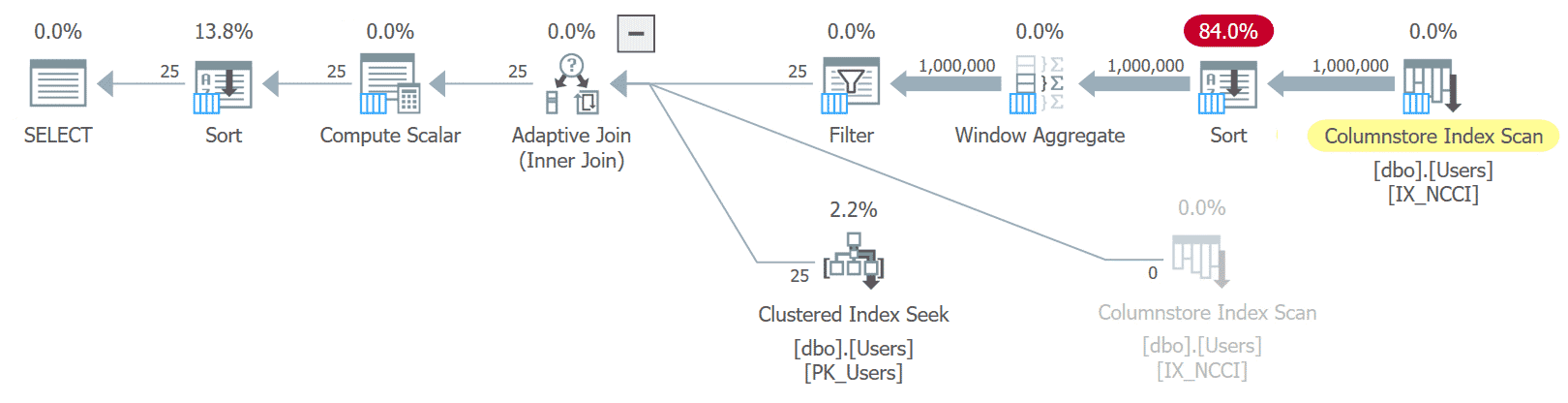
And while they both say they represent 84%, they’re not the same – those are relative (estimated) costs of two very differently-costed plans.
Even in the best case scenario, where the columnstore index does help drive down duration, you still need to account for the overhead involved, and it might not always turn out in your favor.
Another technique
A way I have improved this in a few scenarios is to index a computed column representing the first n characters of the longer string. Where to peg n depends on the nature of the data, and has to allow for unexpected sort order if there are two rows where the first n characters are identical. But let’s say we can be reasonably confident that the first 100 characters are “unique enough”:
ALTER TABLE dbo.Users ADD AboutMePrefix AS (CONVERT(nvarchar(100), AboutMe));
CREATE INDEX IX_AboutMe ON dbo.Users(AboutMePrefix);
In order to take advantage of this, our code needs to conditionally swap out the original column name with the computed column:
...
N'SELECT UserID, rn = ROW_NUMBER() OVER
(ORDER BY ', QUOTENAME(CASE @SortColumn
WHEN N'AboutMe' THEN N'AboutMePrefix'
ELSE @SortColumn END,
N' ', @SortOrder, ')
FROM dbo.Users
...
Now we get performance much more in line with sorting based on any other narrow index:

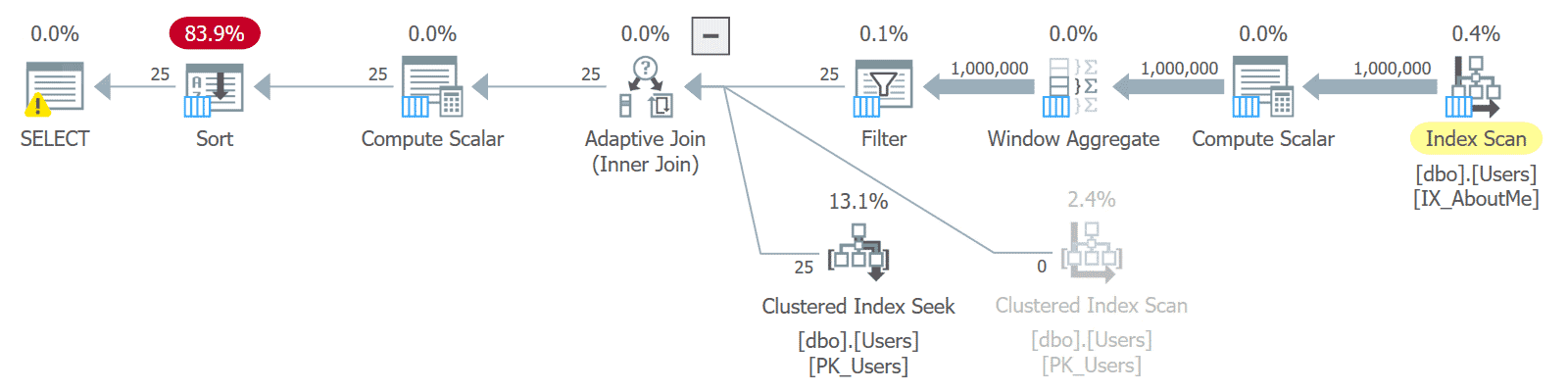
You can play with the PERSISTED option, but this may add unnecessary storage – it’s a common misconception that computed columns must be declared as PERSISTED to be indexed, which isn’t true, though there are cases where persisting the column is important.
Neither choice avoids maintenance overhead, of course. Like any index or computed column, you need to weigh the benefit it provides against the maintenance cost it creates.
At the end of the day, if people are changing their AboutMe content a lot, or if there just aren’t that many people browsing users and sorting by that column, then you may be better off just letting that specific paging operation continue to be slow.
What if I can’t change the schema?
If you can’t change the structure of the Users table, there are other ways to achieve a similar outcome. For example, you could have a separate table with just the AboutMePrefix and UserID columns, and maintain it manually (for real-time consistency, using triggers; or, if there can be a sync delay, through other scheduled means). When the sort is specified on that column, you dynamically swap in the new table instead of Users in the original CTE, e.g.:
...
FROM dbo.', CASE @SortColumn
WHEN N'AboutMe' THEN N'Users_AboutMePrefix'
ELSE N'Users' END, N'
...
You could also consider indexed views.
Of course, everything in this post violates pure relational principles, but that’s a problem for another day…
Conclusion
In a future post, I’ll talk about filtering, including trailing wildcard searches against LOB columns – which can use the computed column if the pattern is short enough. Sometimes, though, pagination is just destined to hurt, and for advanced searching of large string columns, it might be time to look outside SQL Server (e.g. Elasticsearch).
The post Pagination and ordering by large values appeared first on Simple Talk.